
Empirical comparison and analysis of machine learning-based approaches for druggable protein identification
DOI:
https://doi.org/10.17179/excli2023-6410Keywords:
druggable proteins, sequence analysis, bioinformatics, machine learning, deep learning, ensemble learningAbstract
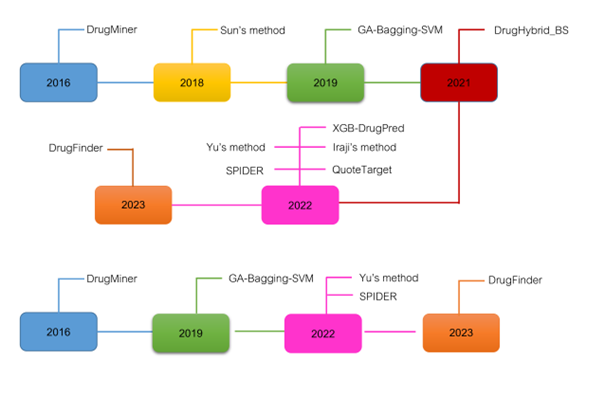
Efficiently and precisely identifying drug targets is crucial for developing and discovering potential medications. While conventional experimental approaches can accurately pinpoint these targets, they suffer from time constraints and are not easily adaptable to high-throughput processes. On the other hand, computational approaches, particularly those utilizing machine learning (ML), offer an efficient means to accelerate the prediction of druggable proteins based solely on their primary sequences. Recently, several state-of-the-art computational methods have been developed for predicting and analyzing druggable proteins. These computational methods showed high diversity in terms of benchmark datasets, feature extraction schemes, ML algorithms, evaluation strategies and webserver/software usability. Thus, our objective is to reexamine these computational approaches and conduct a comprehensive assessment of their strengths and weaknesses across multiple aspects. In this study, we deliver the first comprehensive survey regarding the state-of-the-art computational approaches for in silico prediction of druggable proteins. First, we provided information regarding the existing benchmark datasets and the types of ML methods employed. Second, we investigated the effectiveness of these computational methods in druggable protein identification for each benchmark dataset. Third, we summarized the important features used in this field and the existing webserver/software. Finally, we addressed the present constraints of the existing methods and offer valuable guidance to the scientific community in designing and developing novel prediction models. We anticipate that this comprehensive review will provide crucial information for the development of more accurate and efficient druggable protein predictors.
Downloads
Published
How to Cite
License
Copyright (c) 2023 Watshara Shoombuatong, Nalini Schaduangrat, Jaru Nikom

This work is licensed under a Creative Commons Attribution 4.0 International License.
Authors who publish in this journal agree to the following terms:
- The authors keep the copyright and grant the journal the right of first publication under the terms of the Creative Commons Attribution license, CC BY 4.0. This licencse permits unrestricted use, distribution and reproduction in any medium, provided that the original work is properly cited.
- The use of general descriptive names, trade names, trademarks, and so forth in this publication, even if not specifically identified, does not imply that these names are not protected by the relevant laws and regulations.
- Because the advice and information in this journal are believed to be true and accurate at the time of publication, neither the authors, the editors, nor the publisher accept any legal responsibility for any errors or omissions presented in the publication. The publisher makes no guarantee, express or implied, with respect to the material contained herein.
- The authors can enter into additional contracts for the non-exclusive distribution of the journal's published version by citing the initial publication in this journal (e.g. publishing in an institutional repository or in a book).


